“A inteligência artificial não existe simplesmente. Ela precisa ser treinada”, diz o sociólogo
A visão distópica de manchetes e pesquisas que anunciam a substituição do trabalho humano por robôs, esta mudança radical de uma completa automação, “provavelmente nunca chegará sem a contribuição do trabalho digital humano”, diz o sociólogo francês Antonio Casilli. Em conferência ministrada no “XIX Simpósio Internacional IHU Homo Digitalis. A escalada da algoritmização da vida em tempos de pandemia”, em dezembro do ano passado, o professor do Institut Polytechnique de Paris expôs a realidade de inúmeras pessoas que vivem em países em desenvolvimento e realizam “microtrabalho digital” para plataformas como Amazon, Facebook e Uber, a fim de “treinar” o que ele denomina de “inteligência artificial falsa”.
As atividades desenvolvidas por esses trabalhadores digitais que atuam em fazendas de cliques, moderando conteúdos nas redes sociais e treinando a inteligência artificial de produtos a serem lançados no mercado, demonstram, de um lado, “o mito da substituição robótica” e, de outro, a piora das condições de trabalho. “A moderação de conteúdos é o que nos permite ver o Facebook e nunca encontrar, na melhor das hipóteses, imagens violentas ou mensagens de mau gosto, insultos, conteúdos adultos que nem sempre são apropriados. Como isso acontece? Evidentemente, o Facebook sustenta que o faz via inteligência artificial. Então, existe uma inteligência artificial tão competente que nunca vemos nenhum conteúdo problemático em sua plataforma. A situação é completamente diferente. Há equipes de pessoas que são recrutadas e que trabalham, mais ou menos, nas mesmas condições dos microtrabalhadores do Amazon Mechanical Turk ou do Rater Hub, e essas pessoas não avaliam conteúdos ou produzem dados, nem treinam dados como os demais. Na verdade, elas recebem – ou recebem microssalários – para assistir vídeos e avaliar se esses vídeos são apropriados ou não, julgam fotos, considerando se são pornográficas, eróticas ou sugestivas. Leem mensagens e decidem se uma mensagem pode ser enviada a alguém no Facebook e alcançar uma certa audiência”, informa.
De acordo com Casilli, as pesquisas recentes sobre o impacto das tecnologias focam nas consequências socioeconômicas da inteligência artificial e nos efeitos da automação nos processos empresariais. Esse tipo de abordagem, destaca, analisa “algo que acontece no fim do processo produtivo”. Sua proposta, ao contrário, consiste em perguntar “O que acontece antes do uso?”, ou seja, qual é a mão de obra necessária para produzir a inteligência artificial. “Olhemos então para esta lacuna no conhecimento que temos hoje, ou seja, o fato de que não conhecemos o suficiente sobre os modos atuais de produção, de aprendizagem de máquina e das soluções intensivas de dados. Precisamos olhar para a geração, preparação, anotação de dados e verificar os resultados das análises algorítmicas em que se baseiam as soluções de aprendizagem de máquina. Todos esses elementos possuem um impacto social e econômico considerável e, também, carregam muitos riscos sociais”, assegura.
Casilli refere-se ao que chama de “robôs humanos, pessoas contratadas para ensinar os carros autônomos a dirigir” ou para realizarem outras atividades digitais pelas quais recebem um ou dois centavos por microatividades realizadas. Essas pessoas, que trabalham para conglomerados europeus, norte-americanos e asiáticos, “formam ecossistemas industriais inteiros que se especializam em fornecer esse tipo de dados” e vivem nas cidades de Bangalore e Hyderabad – dois ‘vales do silício’ na Índia –, na China, nas Filipinas, Bangladesh e na América do Sul, particularmente na Colômbia e na Venezuela.
A seguir, reproduzimos a conferência de Casilli no formato de entrevista.


Antonio Casilli (Foto: Wikimedia Commons)
Antonio Casilli é professor titular de Sociologia da Telecom Paris, a escola de telecomunicações do Institut Polytechnique de Paris, e pesquisador do Interdisciplinary Institute on Innovation (i3). Também é pesquisador associado do LACI-IIAC (Centro de Antropologia Interdisciplinar Crítica da École des Hautes Études en Sciences Sociales - EHESS, Escola de Estudos Avançados em Ciências Sociais). Além disso, é membro do corpo docente do Nexa Center for Internet and Society (um instituto da Universidade Politécnica de Torino).
IHU On-Line - Os robôs roubarão os nossos empregos?
Antonio Casilli - Comecemos com alguns dos títulos que a imprensa produziu nos últimos anos: “Robôs podem substituir seres humanos em 1/4 no número de empregos até 2030 nos EUA”. “Robôs substituem empregos: potencialmente 200 mil cortes no horizonte”. E a pergunta eterna: “Os robôs e, em geral, as tecnologias roubarão os nossos empregos?” Essa visão distópica é transmitida não só por meio da imprensa, mas também pelo discurso de especialistas e acadêmicos. Em particular, essa ideia de centenas de milhares de postos de trabalho desaparecendo por volta de 2030 foi popularizada no artigo intitulado “The Future of Employment”, publicado em 2012 por Carl Benedikt Frey e Michael Osborne, pesquisadores da Universidade de Oxford. Segundo o artigo, o número de empregos destruídos pela automação e, especificamente, pela aprendizagem de máquinas e robôs móveis equivaleria a 47% dos empregos em um país como os Estados Unidos. Evidentemente, outros estudos questionaram a metodologia e desafiaram estes resultados, como aquele publicado logo depois pela Organização para a Cooperação e Desenvolvimento Econômico - OCDE, mostrando que o artigo superestimava o número de empregos substituídos pela automação. Segundo esse novo estudo, apenas 9% dos empregos estariam em perigo por causa da automação.
Isso não impediu os autores, especialmente Carl Benedikt Frey, de repetirem o mesmo tipo de profecia distópica, particularmente nos últimos tempos, quando a Covid-19 atingiu o mundo inteiro e nos vários países onde o lockdown foi imposto. Diante do fato de que centenas de milhares de pessoas foram forçadas a trabalhar de casa, ou precisaram parar de trabalhar, Benedikt Frey e outros especialistas sustentaram que, nesse caso, a automação iria se impor simplesmente pelo fato de os seres humanos estarem numa posição difícil, de trabalharem juntos e de trabalhar em locais específicos, como fábricas e escritórios.
IHU On-Line - Estamos enfrentando o fim do trabalho ou, especificamente, do trabalho como o conhecemos, como uma atividade realizada em locais e organizações específicos?
Antonio Casilli - Novamente, nem todos concordam com esses resultados porque nem todos concordam com o tipo de ideia subjacente a artigos como esses. Em especial, há quem desafie que a própria ideia de inovação, e a inovação tecnológica em particular, conduz necessariamente à perda de empregos. David Autor, por exemplo. Economista do MIT, ele vem argumentando, em vários artigos, como este intitulado “Por que ainda existem muitos empregos?”, que o ganho em produtividade, introduzido pela inovação tecnológica, às vezes pode ter resultados inesperados. Por exemplo, peguemos os dispensadores automáticos de dinheiro implementados nos bancos desde o fim da década de 1980. Nesse caso, esperaríamos que essas máquinas substituíssem os funcionários dos bancos, mas o que aconteceu é que, no mundo todo, a própria possibilidade de abrir novas agências bancárias com um custo menor incentivou os donos de bancos a abrirem mais agências, e estas determinaram o aumento no número de pessoas empregadas no setor bancário. Esse é só um exemplo do fato de que, por um lado, existe a ameaça de vermos alguns tipos de trabalhos sendo destruídos e, em outros casos, existe a possibilidade de vermos alguma forma nova de emprego surgir ou, como no caso bancário, ver uma evolução nas habilidades exigidas para trabalhar em um banco.
Atualmente, o funcionário de banco não só conta o dinheiro e o entrega ao cliente. Às vezes, ele é um conselheiro ou assessor de finanças. Em alguns casos, precisa desenvolver novas habilidades, como escutar o que o cliente diz, ou o que o cliente procura, o tipo de investimento que este cliente imagina, e assim por diante. Ele lembra mais um psicólogo ou, em alguns casos, um confessor religioso, do que um consultor, como costumava ser.
Na verdade, o fato é que esta profecia distópica da mão de obra humana tem estado presente entre nós há séculos. Ela começou no início do século XIX, no começo da primeira revolução industrial, com pensadores e economistas como Thomas Mortimer, David Ricardo ou Andrew Ure. Cada um a seu modo, eles tentam explicar que as tecnologias são pensadas para salvar a mão de obra e que, em alguns casos, as tecnologias poderiam ser o fim de certas atividades ou de todas as atividades. Mas esse não é um resultado que acontece necessariamente. Em alguns casos, as tecnologias que salvam a mão de obra andam de mãos dadas com tecnologias que são úteis aos seres humanos e para o trabalho humano, como Thomas Mortimer costumava explicar. Ou, em outros casos, como David Ricardo argumentava, algumas tecnologias não necessariamente são empregadas pelos capitalistas e investidores porque são caras demais, e a mão de obra humana ainda é a opção melhor e mais barata.
IHU On-Line - O que acontece para que essa noção da substituição robótica da mão de obra humana seja tão dominante e tão difundida?
Antonio Casilli - O fato é que quando se trata de analisar as tecnologias, as pesquisas atuais, especialmente aquelas que enfocam as consequências socioeconômicas da inteligência artificial e das tecnologias inteligentes, tendem a enfocar o uso de inteligência artificial na automação de processos empresariais. E, quando focamos no uso, estamos analisando algo que acontece no fim do processo produtivo.
Pelo contrário, a pergunta que faço, e aquela que todos os que olham para a mão de obra necessária para produzir inteligência artificial, é: O que acontece antes do uso? Olhemos então para esta lacuna no conhecimento que temos hoje, ou seja, o fato de que não conhecemos o suficiente sobre os modos atuais de produção, de aprendizagem de máquina e das soluções intensivas de dados. Precisamos olhar para a geração, preparação, anotação de dados e verificar os resultados das análises algorítmicas em que se baseiam as soluções de aprendizagem de máquina. Todos esses elementos possuem um impacto social e econômico considerável e, também, carregam muitos riscos sociais.
Basicamente, argumentamos que as tecnologias inteligentes predicam-se na plataformização, e a plataformização, por sua vez, predica-se na mão de obra (no trabalho) digital humana. Para explicar isso, precisamos nos perguntar por que a plataformização é tão importante. Ora, porque as plataformas põem em prática um novo tipo de trabalho, chamado trabalho digital. Mas o que é trabalho digital exatamente? É a “dataficação” e a “tareficação” das atividades humanas. Por dataficação, quero dizer que todo gesto humano produtivo – atividade e ocupação – acaba virando um processo produtor de dados. E também um processo gerido por dados. Em seguida, ele é também tareficado, porque se reduz a simples tarefas, a comportamentos simples e fragmentados, que são capazes de ser conectados e misturados para produzirem aquilo que conhecemos como tecnologias inteligentes.
Existem três tipos de trabalho digital que acontecem nas plataformas. O primeiro tipo é conhecido como trabalho sob demanda: os típicos Uber, Lyft, Glovo, Deliveroo, Uber Eats. A atividade, realizada via aplicativos, se restringe geograficamente. Ela conecta-se a uma área urbana, a uma cidade, um bairro. Não podemos solicitar um motorista em São Paulo, se estamos em Salvador, na Bahia. É claro que essas atividades foram impactadas pesadamente pela Covid-19 a ponto de perdermos muitos motoristas de aplicativo. Por outro lado, a visibilidade e a simples força social e política dos usuários e dos motoristas e entregadores está maior do que antes da pandemia.
Em seguida, temos o segundo grupo do trabalho digital, chamado de microtrabalho. O microtrabalho é um tipo de atividade não muito conhecido ao redor do mundo, mas que é geral, está presente em vários países e é realizado por milhões de pessoas. Em alguns casos, é um trabalho realizado por usuários de plataformas especializadas, como o Amazon Mechanical Turk, onde, se somos trabalhadores, podemos procurar por trabalhos simples. Chamam-se microtarefas e pagam alguns poucos centavos em troca de uma atividade que dura, em alguns casos, menos de um minuto. Trabalhamos menos de um minuto e ganhamos menos de um centavo, em alguns casos.
Essa não é exatamente a espécie de atividade que buscaríamos se quiséssemos ter uma fonte de renda estável. No entanto, em vários países, visto os problemas políticos e econômicos pelos quais passam alguns países em desenvolvimento, esse tipo de atividade tem se tornado mais popular. Provavelmente, conhecemos pessoas que, especialmente desde o começo da Covid-19, começaram a trabalhar nesse tipo de plataformas, que às vezes se mascaram como atividade onde podemos ganhar algum dinheiro, ou que simplesmente clicamos em coisas que não conhecemos exatamente. Em seguida, veremos no que clicamos e o que estamos fazendo exatamente.
Finalmente, temos o terceiro tipo de trabalho digital. Chama-se trabalho social em rede. É a atividade que acontece nas mídias sociais e, em geral, em plataformas não especializadas, como o Google, o Facebook, o Instagram, o YouTube. Poderíamos pensar que esse tipo de trabalho digital se limita à atividade de produzir conteúdos. Naturalmente, há muito disso. Mas, até certo ponto, cada um de nós, mesmo se jamais postamos mensagens, imagens ou vídeos, estamos produzindo dados e metadados. Para essas plataformas, de alguma forma nós somos produtores de valor.
Há outras atividades realizadas em rede e que são importantes para fazer com que essas plataformas existam. Por exemplo, pensemos nos moderadores. Os moderadores são os que filtram e denunciam o conteúdo considerado problemático e, evidentemente, foram impactados pesadamente pela Covid-19. Provavelmente você já notou que, ao denunciar um conteúdo no Twitter, viu uma mensagem desde março que diz: “Obrigado por denunciar este conteúdo. Infelizmente, nossas equipes de moderadores não estão trabalhando a todo vapor por causa da Covid-19”. Essas pessoas nem sempre podem trabalhar de casa. Em alguns casos, são microtrabalhadores. Em alguns casos, eles podem trabalhar de casa. Mas, visto o tipo sensível de dados com os quais precisam lidar – é preciso analisar o conteúdo, o seu perfil, suas mensagens privadas – eles não podem trabalhar de casa, onde há outras pessoas, como filhos, por exemplo.
Comecemos analisando o trabalho sob demanda e enfoquemos naquela que é provavelmente a plataforma mais importante, o Uber, empresa que não só teve um enorme sucesso cultural – virou uma expressão: uberizar algo é fazê-lo mais parecido com o Uber –, mas também se apresentou como modelo de inovação paradigmático, pois impacta pesadamente na forma como a mão de obra se organiza.
A empresa Uber incorpora um modo específico de organizar a mão de obra humana, não só porque é famosa por descrever seus motoristas como parceiros e por não contratá-los, mas principalmente porque tais motoristas são, antes de mais nada, provedores de dados. De acordo com vários dos motoristas entrevistados pela imprensa, eles dedicam uma boa parcela do seu tempo aguardando a solicitação de uma corrida e, enquanto aguardam, estão no aplicativo do Uber móvel produzindo dados. Segundo algumas estimativas, apenas 41% do tempo é usado para dirigir do ponto A ao ponto B. O restante do tempo é descrito como quilômetros perdidos, expressão que descreve o fato de serem horas inúteis. E essas horas são, na verdade, gastas fornecendo dados para a plataforma.
Que tipo de dados são produzidos pelos motoristas de Uber? Antes de mais nada, são os dados pessoais, relativos ao próprio perfil do motorista. Eles precisam escolher a foto certa, digitar o próprio nome e providenciar uma série de informações pessoais, que são importantes para os que trabalham no Uber. Em seguida, os motoristas de Uber produzem dados sempre que definem um período específico de horas a trabalhar e que lhes permitirá ganhar mais. Eles então precisam enviar e receber mensagens, e essas mensagens são dados que são trocados com uma central, também com outros motoristas e, evidentemente, clientes.
Dados de localização são também importantes. São produzidos principalmente na utilização de vários aplicativos para negociar o melhor trajeto possível entre o ponto inicial de uma corrida e o seu destino. Especialmente porque o aplicativo do Uber tem o terrível hábito de sugerir trajetos que são linhas retas. Evidentemente, isso é impossível numa cidade regular. Portanto, os motoristas de Uber precisam trocar entre aplicativos de Uber e outros aplicativos, tais como Waze, que fornecem melhores trajetos de GPS e que consideram problemas de tráfego e acidentes.
Finalmente, temos o placar de reputação. O placar de reputação é realmente uma Espada de Dâmocles pendendo sobre a cabeça dos motoristas de Uber. Principalmente porque esse é o placar que eles alcançam com base nas avaliações que são deixadas pelos usuários. Sempre que pego um Uber, normalmente deixo uma avaliação da performance do motorista. Se foi um bom motorista, se chegou no horário certo, se o carro estava limpo o suficiente, se estava disponível para conversar, se era muito falador ou silencioso demais, e assim por diante. Esse modo subjetivo e, em alguns casos, extremamente arbitrário de avaliar a performance dessas pessoas lhes são realmente importantes, porque, se o placar cai abaixo de um certo limite – em alguns casos, o limite é 4,7 –, eles são desativados, o que se aproxima de uma demissão pela empresa. Digo “se aproxima”, porque, segundo a plataforma, ela nunca os contratou.
Todos esses dados são necessários para a combinação algorítmica do Uber que, nesse caso, é fundamental para pôr em prática um sistema de gerenciamento algorítmico desta mão de obra. Por gerenciamento algorítmico quero dizer que o trabalho, na plataforma, regula-se por algoritmos, que nem sempre é o caso em empresas regulares e negócios tradicionais, onde a gerência se estabelece sobre regras ou critérios, tais como a ação planejada.
Nesse caso, existe uma adaptação em tempo real da solicitação por mão de obra: a solicitação que é dirigida aos motoristas de Uber e o incentivo que eles precisam para fornecerem essa mão de obra. Tudo isso se alcança via algoritmos específicos. O algoritmo patenteado de busca de preços, usado pelo Uber para combinar a oferta e demanda de mão de obra, não é segredo. Na verdade, o setor de pesquisa e desenvolvimento da empresa publicou vários artigos explicando como este algoritmo funciona. Peguemos um exemplo, publicado num artigo de 2015, que descreve uma situação muito específica ocorrida em Nova York, em 21 de março de 2015. Após a apresentação da estrela pop Ariana Grande, milhares de pessoas estavam no Madison Square Garden e precisavam de uma carona para casa. Então, alguns milhares conectaram-se ao aplicativo móvel e, com base no fato de que havia um aumento enorme no número de usuários conectados num local específico, o algoritmo pôde estimar o surto na demanda de caronas. O que, claramente, leva a uma outra consequência, a uma outra ação: o algoritmo estabeleceu que o preço de cada corrida deveria ser multiplicado por um coeficiente. Para os consumidores, isso significou que a mesma corrida que eles pagariam dez dólares antes, agora ficaria em torno de 40, 50, 70 dólares. Para os motoristas de Uber, foi uma boa notícia, pois significava que ganhariam mais pela mesma corrida, enquanto, do lado dos usuários, a situação muda. O mapa da cidade de Nova York muda porque ocorre uma nova zona vermelha. Uma zona vermelha é onde os preços são mais altos, então os motoristas de Uber são incentivados, são motivados, encorajados a se dirigirem para a região. Nesse caso, era a região em torno do Madison Square Garden, e foi exatamente o que aconteceu.
Várias centenas e, em alguns casos, milhares de motoristas se dirigiram para a região do Madison Square Garden e pegaram os usuários que estavam dispostos a pagar um preço mais elevado. Em outros casos, alguns consumidores decidiram não gastar 40 ou 70 dólares, mas aguardar para que o preço voltasse ao normal. Assim, nesse caso, eles passaram mais tempo na plataforma produzindo dados.
Todos os dados produzidos, seja pelos motoristas, seja pelos usuários do Uber, importam porque são, evidentemente, monetizados. São dados que se transformam em dinheiro, porque o Uber vende esses dados a cidades ou marcas, a outras plataformas para fazerem o que quiserem. Principalmente para anúncios direcionados e para a otimização do tráfego em cidades e municípios. Mas existe também outro uso para esses dados, e é principalmente o uso de dados para a automação.
Os dados são usados para treinar um tipo específico de processo automatizado que, para o Uber, são seus carros sem motoristas. É importante enfatizar que eles descrevem esses carros como sem motoristas. Esses veículos autônomos são, evidentemente, imaginados como uma espécie de “boudoir” [quarto decorado] sobre rodas, onde ninguém seria o motorista e todos seriam apenas passageiros. A situação também é diferente porque, hoje, inexistem veículos automatizados de nível 5. Segundo CEOs e funcionários da Tesla e da Volkswagen, jamais veremos algo acima do nível 3 – a automação limite que conhecemos atualmente –, em que alguém dirige esses carros, mas a pessoa não é descrita como motorista. Ela é descrita como uma operadora de direção, alguém que está ali para evitar que esses carros colidam com algo, ou para ajudar outros passageiros, assumindo o volante em situações que poderiam acabar sendo fatais, porque um carro pode matar alguém, evidentemente.
O fato de o trabalho destes motoristas ser tão subestimado, pouco enfatizado e, ultimamente, invisibilizado pelas plataformas, levou a algumas consequências terríveis, como a primeira casualidade humana: uma pessoa morta por um carro sem motorista, por assim dizer. Aconteceu em março de 2018, no Arizona. A seguir, vemos duas fotos. A primeira, com um círculo vermelho, é tirada do ponto de vista do carro. A câmera aponta na direção exterior, e a pessoa no círculo vermelho é a vítima do acidente. Essa foto foi tirada um segundo antes do acidente fatal.
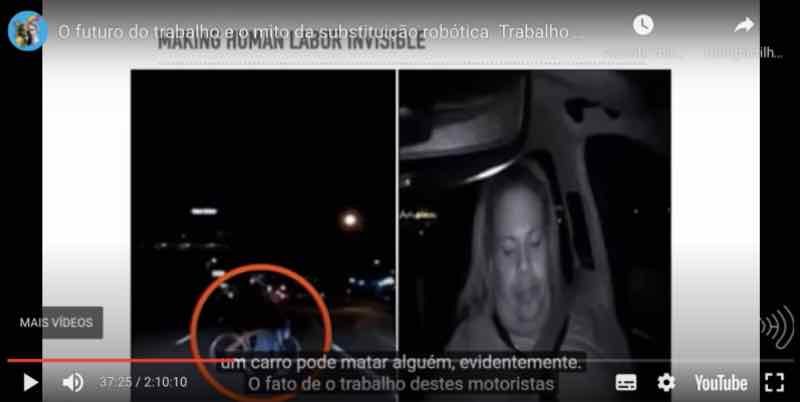
Imagem da conferência
Vejamos a segunda foto [ao lado e acima]. Essa foi tirada da câmera que aponta na direção do interior do carro, um segundo antes do acidente. Como podemos ver, há alguém no assento do motorista. Essa pessoa não está dormindo. Ela não está assistindo um programa de TV no tablet. Na verdade, ela está assistindo a progressão do carro no tablet. Portanto, nesse caso, significa que, se a pessoa tivesse recebido um treinamento melhor, se tivesse ficado claro que o seu trabalho era crucial para evitar situações como esta, se o Uber não tivesse subestimado a importância de alguém sentado no banco do motorista, esse acidente poderia ter sido evitado.
Quando digo que as empresas, como a Uber, fazem de tudo para invisibilizar esta mão de obra humana, não é uma metáfora, não é uma figura de linguagem. É algo que as empresas fazem realmente. Elas buscam esconder estes trabalhadores; escondem dentro dos carros. Como podemos ver, por exemplo, nesta imagem... não é um meme, não é uma foto humorística, nem uma fotomontagem. Trata-se de um protótipo real dos chamados carros sem motorista desenvolvidos pela Ford, nos Estados Unidos. Como podemos ver, o motorista foi disfarçado como um assento do carro para produzir a ilusão de que é um carro sem motorista.

Imagem da conferência
Além dos trabalhadores humanos que ainda são necessários dentro dos carros, existem também outros trabalhadores, uma outra categoria inteira que nos permite trocar para o segundo tipo de microtrabalho digital. Esses trabalhadores não estão dentro dos carros. Estão em locais remotos. Eles são fundamentais para ajudar o carro a aprender a dirigir. Porque os carros autônomos baseiam-se em soluções de inteligência artificial e no aprendizado de máquina. Quando falamos em aprendizado de máquina, também falamos que alguém precisa ensinar esse carro a dirigir e reconhecer diferentes objetos: um outro carro, uma árvore, e assim por diante.
Quem são as pessoas que ensinam os carros a fazerem o que prometem fazer? De acordo com Anthony Levandowski – ele foi o chefe do setor de veículos comerciais do Uber, Otto –, podemos descrever essas pessoas como robôs humanos. Por quê? São elas algum tipo de autômato antropomórfico? Não. São basicamente os humanos que ensinam os robôs, nesse caso, o carro autônomo, a fazerem o que fazem. Isto é, são os treinadores dos dados que são usados para esta inteligência artificial.
Um carro autônomo é, na verdade, um dispositivo que se comunica. Ele se comunica com a plataforma à qual se conecta. Comunica-se com outros veículos conectados. Mas também captura muitos dados de objetos ou comportamentos ao redor. Se alguém cruza a rua, o carro autônomo deve registrar e, então, processar e agir consequentemente. Mas, para que o carro aprenda a agir consequentemente, precisamos injetar dados de qualidade, o que significa dados anotados, filtrados, documentados na inteligência artificial que gerencia o carro.
Os dados, como provavelmente já sabemos, não são anotados desde o começo. Eles precisam ser anotados, precisam ser transformados de dados brutos em dados enriquecidos. Portanto, existem várias plataformas que fornecem esse serviço. Pegam dados brutos, nesse caso, imagens gravadas pelos carros autônomos, e traçam linhas ao redor dos carros, semáforos, pistas de corrida, casas, pessoas cruzando a rua. Em seguida, acrescentam tags, depois fornecem metadados contextuais. Geralmente, quem faz isso são as plataformas comerciais que tendem a se especializar nesse tipo de anotação de dados, e provavelmente uma das melhores plataformas era a Mighty AI. Digo “era” porque no ano passado [2019] a empresa Uber decidiu comprar a Mighty AI e, agora, ela não existe mais. É simplesmente Uber Pesquisa.
Então, a Uber criou uma plataforma que anota esses dados. E quem são as pessoas que anotam esses dados? De acordo com as imagens comerciais da própria empresa, os treinadores desses dados são geralmente jovens, loiros, brancos e trabalham em ambientes que lembram uma start-up. Um jeito extremamente descontraído de trabalhar. Há um garoto e uma garota. Provavelmente temos uma tensão romântica aí. Portanto, um ambiente ideal para trabalhar. Bem, a realidade é totalmente diferente.
Esses robôs humanos, as pessoas contratadas para ensinar os carros autônomos a dirigir, são geralmente contratados em países em desenvolvimento ou emergentes. Formam ecossistemas industriais inteiros que se especializam em fornecer esse tipo de dados. Por exemplo, nas cidades de Bangalore e Hyderabad – dois “vales do silício” da Índia –, há uma enorme quantidade de pessoas especializando-se no enriquecimento desses dados.
Por que as plataformas precisam contratar este tipo de trabalhador? A razão é que as soluções de inteligência artificial que nós, enquanto sociedade, produzimos não são exatamente o tipo de inteligência artificial apresentada na imprensa ou nos artigos mais visionários dos pioneiros da inteligência artificial.
As soluções de inteligência artificial existentes no mercado se assemelham aos assistentes virtuais, como Siri e Cortana, aqueles que temos nos nossos smartphones, na Alexa ou no Google Home, que são usados como alto-falantes inteligentes (smart). Ou estas soluções são aquele tipo de inteligência artificial usado para conectar carros, sistemas de autopiloto.
Portanto, não é uma inteligência artificial geral. É uma inteligência artificial estreita. Eis a definição dada por Ray Kurzweil, chefe de engenharia do Google, e esta inteligência artificial estreita se especializa em ações específicas, decisões ou domínios da atividade humana. A maior parte desse tipo de inteligência artificial depende do aprendizado de máquinas. Qualquer tipo de aprendizagem de máquina: aprendizagem profunda, redes neurais, anúncios gerativos, redes convolucionais e outros tipos de redes, mas principalmente baseiam-se no aprendizado estatístico – e o aprendizado estatístico depende de dados. Portanto, precisamos de dados para produzir estas soluções de inteligência artificial estreita.
Para treinar estas soluções em inteligência artificial estreita, algumas plataformas especializaram-se na produção de dados anotados, como o Amazon Mechanical Turk, que foi inventado por Jeff Bezos – ou, pelo menos, lançado por ele em 2006. Fia-se em uma patente apresentada em 2001, e o nome nada tem a ver com a Turquia, mas com o autômato lendário inventado no século XVIII.
O Mechanical Turk (turco mecânico) era um jogador robótico de xadrez disfarçado de turco otomano, inventado em 1769 por Wolfgang von Kempelen, inventor austríaco. O turco mecânico deveria ser a primeira inteligência artificial porque ele desafiaria e, claro, venceria qualquer adversário humano de xadrez. Mas havia um pequeno problema, na verdade. Esse robô era uma farsa. Ele não era inteiramente robótico. Não simulava os processos cognitivos de um jogador de xadrez, mas simplesmente continha dentro de seu mecanismo uma pessoa – um ser humano – que podia mover as peças sobre o tabuleiro. Já a pergunta sobre quem era essa pessoa fica para interpretação de cada um. Há várias hipóteses. Uns dizem que era um soldado cujas pernas foram amputadas após uma batalha. Em outros casos, o indivíduo é descrito como um garotinho magro ou, ainda, é descrito como um anão. De qualquer forma, nunca o descreveram como um grande mestre de xadrez. Essa pessoa não era um gênio. Era apenas alguém que tinha um tipo de deficiência, por ser pequena demais ou porque era anã, ou porque tinha as pernas amputadas, ou ainda era pequena demais para trabalhar. Na verdade, o Amazon Mechanical Turk não se baseia na ideia de colocar a trabalhar pessoas com deficiência. Não necessariamente. A ideia é que, para alcançar uma boa performance intelectual, não precisamos de gênios, precisamos de pessoas normais. É o mesmo princípio subjacente ao Amazon Mechanical Turk, exceto que, no caso do mecânico turco do século XVIII era uma única pessoa a mover o único robô e, no caso do Amazon Mechanical Turk, há centenas de milhares de pessoas produzindo aquilo que Jeff Bezos descreve como “inteligência artificial artificial”, isto é, inteligência artificial falsa.
Quando Jeff Bezos diz que o Amazon Mechanical Turk produz inteligência artificial artificial, ele exagera um pouco, ou pelo menos em alguns casos. A questão é que nem sempre esta plataforma pode ser usada para estimular um sistema de inteligência artificial, mas que a plataforma é importante para treinar e, em alguns casos, para verificar o que o sistema de inteligência artificial e as tecnologias fazem.
Por exemplo, imaginemos que temos de treinar uma solução de software OCR que reconheça o conteúdo de um ticket de compras no Walmart. Ou, por exemplo, que precisamos treinar um carro autônomo a dirigir. Ou imaginemos que precisamos treinar o algoritmo gerador de playlists do Spotify. Teremos que ensinar o algoritmo a reconhecer diferentes gêneros musicais e como reuni-los. Para fazer isso, precisamos produzir dados e esses dados precisam ser, evidentemente, anotados e enriquecidos.
IHU On-Line – Quais são os limites e possibilidades da automação?
Antonio Casilli - Empresas que querem automatizar alguns processos empresariais, por exemplo, a contabilidade ou qualquer outro processo, podem ir ao Amazon Mechanical Turk e contratar, por um período limitado de tempo, pessoas que realizarão microtarefas. Visto que essas microtarefas levam alguns poucos segundos, em alguns casos alguns minutos, para serem realizadas, “contratar” não é exatamente a palavra certa. Essas pessoas são recrutadas e, em seguida, descartadas. Isso significa que, após terem finalizado a microtarefa, nada as conecta ao cliente, à pessoa que quis o seu trabalho em primeiro lugar. E esses trabalhadores são muito mal pagos. Em alguns casos, um ou dois centavos para realizarem as tarefas. Não há nenhum contrato real que liga os trabalhadores às empresas ou à própria plataforma. A única coisa que a Amazon quer que os microtrabalhadores subscrevam é um acordo geral, como os Termos de Serviços em que qualquer um clicaria para usar uma plataforma ou um aplicativo. Mas, em seguida, essas pessoas são encorajadas a realizar tarefas realmente importantes de treino dos algoritmos e da inteligência artificial. Essas tarefas incluem reconhecer linguagens ou tipos de conversas, escrever palavras, anotar imagens ou isolar elementos, fornecer palavras-chave. Todas são extremamente importantes para o processamento da linguagem natural ou para o reconhecimento de imagens.
Novamente, o problema é sempre quem está realizando essas microtarefas. Quem aceita trabalhar por um tipo tão instável e volátil de ocupação – que não é um emprego, para falar a verdade, apenas uma atividade, uma atividade informal, precária, na melhor das hipóteses, e que é mal paga. Sempre que precisam responder quem são os seus microtrabalhadores, as empresas respondem com o tipo de imagem comercial promocional que vimos antes com o Uber, por exemplo. Esses trabalhadores de dados, esses provedores de dados são descritos como profissionais jovens, residentes em países do Norte global, e geralmente são pessoas brancas. O ponto é que a realidade das equipes de pessoas que de fato treinam e geram esses dados é inteiramente diferente. Como podemos imaginar, as pessoas dispostas a realizar tais trabalhos voláteis por uma quantidade tão pequena de dinheiro vêm de países com renda média muito baixa, como os países em desenvolvimento. Por exemplo, as Filipinas ou Bangladesh.
Portanto, em certo sentido esse tipo de microtrabalho pode se comparar ou equacionar-se a um tipo de offshore, ou seja, uma terceirização para um local distante, normalmente um país mais pobre, onde os salários são mais baixos e onde as pessoas se dispõem a trabalhar em condições piores. Nesse caso, não é um offshore demandando que uma empresa abra uma fábrica ou escritório em um outro país. Elas podem fazer um offshoring virtual, ou seja, uma terceirização com base numa plataforma de processos empresariais num local remoto, com um investimento muito limitado ou sem nenhum investimento. Elas sequer precisam contratar essas pessoas porque os microtrabalhadores que normalmente usam essas plataformas não são contratados.
A Amazon não é a única empresa que lucra com o microtrabalho de treinamento das soluções para a inteligência artificial. A Microsoft, por exemplo, vem usando-o há anos para calibrar e otimizar os seus produtos. Por exemplo, o mecanismo de buscas Bing precisa ser, digamos, melhorado com ajuda de microtrabalhadores que são recrutados em uma plataforma de propriedade da Microsoft. Essa plataforma chama-se UHRS, sigla para Sistema de Referência Humana Universal. O princípio é exatamente o mesmo, com a exceção de que não é aberto a qualquer um como o Amazon Mechanical Turk. O UHRS serve só para a Microsoft treinar as suas próprias inteligências artificiais.
Mas a Microsoft também mostrou que os usuários podem se transformar em microtrabalhadores: usuários simples, regulares de internet, que foi o caso com o experimento Tay. O experimento Tay foi um chatbot – tipo muito simples de inteligência artificial – que deveria simular o comportamento e a personalidade de uma adolescente. O problema ou, na verdade, o desafio foi que a Microsoft decidiu não treinar essa inteligência artificial internamente, mas deixá-la livre de forma que os usuários de internet a treinassem. Grande engano. Em pouco tempo, vários usuários, especialmente trolls vindos da comunidade 4chan [um website no qual os usuários publicam anonimamente, com as postagens mais recentes aparecendo acima das mais antigas], decidiram organizar aquilo que podemos descrever como treinamento adverso, isto é, ensinar Tay a agir de forma problemática. Especialmente, ensinaram a esse chatbot várias opiniões pouco populares e politicamente preconceituosas sobre o uso de drogas, minorias étnicas ou blasfêmia, e outras coisas que fizeram a Microsoft descontinuar o experimento, que, evidentemente, foi um grande fracasso. Mas ele também demonstrou o quanto o treinamento é importante para a criação da inteligência artificial. A inteligência artificial não existe simplesmente. Ela precisa ser treinada. Portanto, um treinamento de qualidade é importante.
Outras empresas como o Google fazem exatamente a mesma coisa que a Microsoft fez com o experimento Tay, mas elas tiveram um maior sucesso. Por exemplo, quando usamos o mecanismo de buscas do Google, este mecanismo funciona – e funciona bem – porque, atrás dele, há uma plataforma já com mais de dez anos de idade chamada Rater Hub, onde microtrabalhadores são recrutados para avaliar e conferir os resultados algorítmicos das buscas do Google.
O Rater Hub do Google, ou seja, a plataforma de microtrabalho dessa empresa, foi introduzido por volta de 2007. Basicamente, funciona assim: sempre que um usuário de internet usa o mecanismo de buscas do Google para procurar algo, alguém recebe no Rater Hub uma tarefa que consiste em checar se os resultados submetidos pelo mecanismo de buscas do Google foram apropriados. Por exemplo, estamos procurando por uma farmácia em Lille, na França, mas o mecanismo de buscas traz resultados do Brooklyn, nos Estados Unidos. Há algo errado, e algo precisa ser corrigido. Então, nesse caso, o avaliador – o microtrabalhador – pode pôr uma avaliação vermelha, que significará que é um exemplo ruim de resultado. Em outros casos, alguns resultados de buscas introduzem websites que são inapropriados para o usuário. Por exemplo, são websites adultos, ou websites que contêm notícias falsas, ou politicamente extremistas e, nesses casos, os endereços podem ser marcados pelos microtrabalhadores no Rater Hub.
De novo, por serem microtrabalhadores, essas pessoas recebem pela tarefa. Recebem uma pequena quantidade de dinheiro, geralmente alguns centavos a cada checagem de um resultado de buscas. Mas poderíamos dizer que sempre que usamos o mecanismo de buscas do Google somos, até certo ponto, um provedor de dados. Toda vez que buscamos algo no Google, estamos ensinando os algoritmos de buscas a procurar pelas ocorrências mais comuns de um termo, de uma sentença, de uma expressão. Por exemplo, se procurarmos por “Nova York T...”, mais provavelmente estaremos procurando pelo jornal New York Times. E isso é verdade porque o Google já teve milhões – nesse caso, provavelmente bilhões – de exemplos produzidos pelos usuários para treinar os seus algoritmos.
Mas poderíamos dizer que sempre que usamos um mecanismo de buscas, não temos um trabalho e, do ponto de vista jurídico, não temos. E mesmo do ponto de vista econômico seria difícil demonstrar que algo pelo qual não recebemos seria considerado trabalho. Na verdade, há algo mais acontecendo com o Google. O Google é extremamente competente em convidar as pessoas a produzirem dados para as suas plataformas e seus serviços em geral, e em alguns casos a empresa é muito transparente sobre o fato de que aquilo que as pessoas fazem, ao produzirem dados, é trabalho. Um tipo específico de trabalho, que chamam de “crowd work”, trabalho de uma multidão de usuários. É exatamente o caso com o reCaptcha.
O reCaptcha é algo que você já encontrou alguma vez na vida. É a página que aparece sempre quando queremos recuperar uma senha ou deixar uma mensagem num fórum ou uma mensagem on-line, ou qualquer tipo de atividade dessa natureza. Nesse caso, precisamos demonstrar que não somos robôs. Como afinal demonstrar que não somos um robô? No começo, por volta de 2010, isso era feito via transcrição de palavras enviesadas. Nesse caso, por exemplo, temos “mourning upon”. É difícil ler essas palavras e, nesse caso, um ser humano era capaz de ler, mas não um robô. Portanto, se transcrevêssemos as duas palavras, demonstraríamos ter dado a resposta certa.
Ao mesmo tempo, sempre que transcrevemos essas palavras distorcidas, nós também ensinamos as tecnologias OCR do Google Livros a ler livros escaneados. O problema é que os livros do Google eram escaneados manualmente, o que significa que alguém normalmente colocava a página sobre o escâner. Em alguns casos, a página estava corrompida, ficava distorcida ou o resultado não era legível. Não era legível por um robô, mas alguém, como um ser humano, com um pouco de atenção, poderia interpretar essas palavras, e é isso o que acontece – ou costumava acontecer, na verdade – quando alguém transcrevia palavras para o reCaptcha.
Eu disse “costumava acontecer”, porque, em 2015, algumas poucas centenas de pessoas em Massachusetts deram início a um processo de ação coletiva contra o Google para serem reclassificadas como funcionárias da plataforma, porque durante anos elas usaram esse reCaptcha. Apesar de o juiz decidir em contrário, esse foi um momento de verdade para o Google. A empresa disse: “Muito bem, agora as pessoas estão cientes de que não se trata apenas de um serviço, não é um jogo. Na verdade, é um trabalho que elas fazem para nós”. E assim o Google decidiu descontinuar o antigo reCaptcha e apresentou algo novo.
Em 2015, o reCaptcha foi substituído pelo “No Captcha reCaptcha”, que é o reCaptcha visual com o qual estamos familiarizados atualmente. Às vezes, quando queremos receber uma informação ou acessar website, temos que selecionar quadros com sinais de trânsito, carros, estátuas. Por quê? Porque nesse caso não estamos ensinando o software OCR do Google Livros a fazer aquilo que ele faz, mas estamos treinando a inteligência artificial do carro Waymo. Chama-se Waymo o setor do Google especializado em carros autônomos. Então, basicamente estamos ensinando carros autônomos a reconhecerem sinais de trânsito, semáforos e outros carros. Estamos realizando aquele trabalho que, para o Uber, as pessoas realizam recebendo algo em troca. De uma forma clara e simples... elas são mal pagas, mas, pelo menos, são pagas. Nesse caso, não estamos sendo pagos.
IHU On-Line - Qual a diferença entre o microtrabalho e o trabalho fornecido por um usuário?
Antonio Casilli - Alguém pode dizer que, sim, não recebemos; que, sim, estamos produzindo dados. Mas isso não pode ser considerado como trabalho, porque estamos recebendo um serviço em troca da nossa contribuição. A questão é que esse serviço que recebemos em troca nem sempre é um serviço real – e por “real” quero dizer um serviço pronto para ser colocado no mercado. Em muitos casos, existem os protótipos dos serviços. Por exemplo, os softwares de tradução, como o Bing ou o Google Tradutor. Eles dão uma tentativa. Tentam traduzir com base em alguns exemplos. Mas sempre que apresentam uma tradução, eles também nos convidam a sugerir uma tradução melhor. Portanto, sempre que clicamos em “Sugerir uma edição” no Google Tradutor, somos convidados a fornecer a nossa própria tradução. E o que acontece com a nossa sugestão? Ela é incluída num banco de dados de treinamento e é usada para extrair uma qualidade melhor desse software tradutório.
O mesmo vale para o Facebook. O Facebook às vezes fornece traduções automáticas de postagens e mensagens. No Facebook, podemos clicar em um botão específico e somos convidados a dar uma tradução melhorada. Então o mesmo acontece com o Facebook: fornecemos uma tradução, que é incluída no banco de dados de treinamento e, então, é usada para melhorar esse software de tradução automática.
O Facebook também apresentou o seu próprio serviço em que convida as pessoas a realizarem microtrabalhos gratuitos. Se acessarmos o endereço facebook.com/editor, seremos convidados a dar informações sobre o teatro ou restaurante em que estamos, sobre um filme ou livro. Nesses casos, somos convidados a conferir o endereço e os horários. O que recebemos em troca? Não é dinheiro, mas recebemos selos e algumas recompensas simbólicas que consistem em nos pôr em contato com outros microtrabalhadores ocultos, outros editores do Facebook.
Vemos que esse tipo de atividade é apresentado como um desafio. É apresentado como uma atividade comunitária. Mas ela tem obscurecido as linhas entre trabalho e consumo. Sou um simples usuário do Facebook? Ou estou também trabalhando para o Facebook?
O Facebook é uma plataforma e, como tal, captura o valor produzido pela comunidade de seus usuários. Nesse caso, o Facebook é uma plataforma “lean”. Ela é uma plataforma não proprietária do conteúdo que produz e distribui. Desse ponto de vista, é um meio-termo entre uma fábrica de conteúdos e o mercado de conteúdos. Um mercado de conteúdos não significa que o Facebook venda o conteúdo produzido pelos usuários. Sempre que postamos uma mensagem ou uma foto do nosso gato, o conteúdo não é importante. O Facebook não é como o Flickr, não é como o YouTube. Ele não utiliza o conteúdo dessa forma, mas o monetiza olhando para os metadados, que são disponibilizados a corretoras de dados, agências de anúncios ou marcas que podem usá-los para personalizar as propagandas direcionadas.
Mas, como muitas outras plataformas, a monetização de dados não é a única atividade importante. Os dados são fundamentais também para a automação, como afirmamos antes. Consideremos um exemplo ou uma atividade específica que acontece no Facebook: a moderação de conteúdos. A moderação de conteúdos é o que nos permite ver o Facebook e nunca encontrar, na melhor das hipóteses, imagens violentas ou mensagens de mau gosto, insultos, conteúdos adultos que nem sempre são apropriados. Como isso acontece? Evidentemente, o Facebook sustenta que o faz via inteligência artificial. Então, existe uma inteligência artificial tão competente que nunca vemos nenhum conteúdo problemático em sua plataforma.
A situação é completamente diferente. Há equipes de pessoas que são recrutadas e que trabalham, mais ou menos, nas mesmas condições dos microtrabalhadores do Amazon Mechanical Turk ou do Rater Hub, e essas pessoas não avaliam conteúdos ou produzem dados, nem treinam dados como os demais. Na verdade, elas recebem – ou recebem microssalários – para assistir vídeos e avaliar se esses vídeos são apropriados ou não, julgam fotos, considerando se são pornográficas, eróticas ou sugestivas. Leem mensagens e decidem se uma mensagem pode ser enviada a alguém no Facebook e alcançar uma certa audiência.
Portanto, é um trabalho de moderação realizado por humanos, e esses humanos são pagos. Nesse caso, é claramente um trabalho, apesar do fato de as pessoas serem mal pagas e nem sempre estarem em países onde podem escolher, do ponto de vista do acesso à mão de obra. Mas algo acontece no Facebook quando se trata da moderação de conteúdos, porque simples usuários – pessoas que não recebem nada – estão envolvidos ativamente nessa atividade. Por exemplo, sempre que vemos algo e o consideramos ofensivo, podemos clicar em um botão e denunciar o conteúdo.
O que acontece quando denunciamos e quando também fornecemos detalhes sobre quem pode se ofender com tal conteúdo? Do que se trata o conteúdo? Ele é pornográfico, é um insulto? O que acontece é que o conteúdo não é excluído automaticamente. Ele é enviado a um moderador, e esse moderador humano decide se o conteúdo é apropriado ou não. Portanto, há um tipo de mão de obra humana no começo, porque nenhum conteúdo recebe moderação se ninguém o denuncia, se os usuários não os marcam. Mas, de novo, há um trabalho humano no final desse processo porque existe uma decisão humana, a decisão de um moderador de conteúdos que, eventualmente, decide para um lado. E, no meio, não vemos em lugar algum a inteligência artificial.
Um outro ponto é que o ganho de conteúdos é apenas um aspecto da produção e da cultura de valor do Facebook. Quando se trata do Facebook, o principal sempre são os dados e os dados são produzidos na plataforma via cliques. Isso significa que só precisamos clicar em algo para compartilhar ou adicionar reações e, nesse caso, podemos argumentar que os usuários regulares do Facebook se parecem muito com os produtores de cliques. E esses produtores de cliques são uma categoria específica de trabalhadores chamados “clickfarmers”, fazendeiros de cliques.
As fazendas de cliques são serviços que às vezes se disfarçam de websites ou plataformas onde simplesmente podemos nos inscrever e ganhar por “likes” ou por cliques, além de recebermos para avaliar positivamente um aplicativo ou um site. É o tipo de site usado por estudantes que querem ganhar um dinheiro extra, ou por alguém em apuros financeiros e que deseja ganhar um dinheiro extra no fim do mês.
Evidentemente, a situação em alguns países emergentes e em desenvolvimento é completamente diferente, e estas fazendas de cliques não são usadas por quem quer algum dinheiro extra, mas por quem depende delas como renda primária. Os fazendeiros de cliques não trabalham em suas casas. Eles ficam em fazendas de cliques reais, que são lugares essenciais como este da foto, onde alguém recebe dinheiro, declaradamente muito pouco, para ir de um smartphone a outro e clicar no conteúdo que recebem.
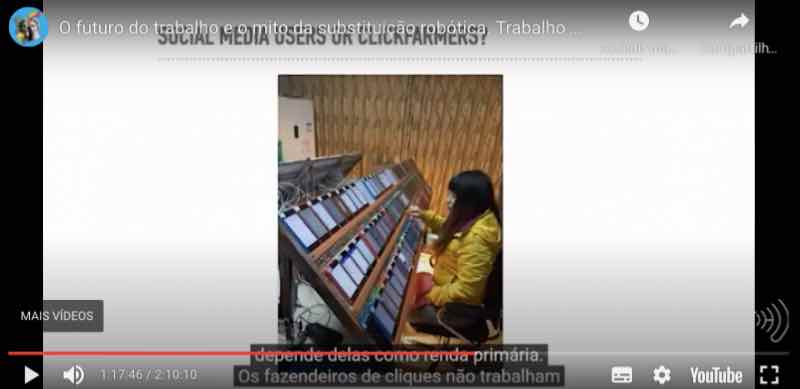
Imagem da conferência
A forma como a inteligência artificial e o trabalho digital necessário para produzi-la é percebida no Norte global e no Sul global divergem, o que requer uma investigação melhor e mais aprofundada. Antes de mais nada, vejamos a localização das empresas que produzem ou, pelo menos, vendem soluções de inteligência artificial. Elas ficam em países do Norte global, como os Estados Unidos e, claro, a Europa. Depois, a Austrália, a Coreia e o Japão, para citar alguns países asiáticos ou do Pacífico. Em seguida, temos os grandes atores localizados atualmente na China e na Índia.
E quanto à mão de obra? Ela nem sempre é local. Isto é, as empresas nos Estados Unidos nem sempre recrutam mão de obra no próprio país. Às vezes, ou em muitos casos, recrutam nas Filipinas ou na Índia, ou nos países do Sudeste asiático, ou mesmo da América do Sul.
A América do Sul é interessante porque atualmente tem explodido no mercado do trabalho digital global. Há um número crescente dessas pessoas na Colômbia ou, de modo significativo, na Venezuela, o que é compreensível, visto a situação política e econômica do país. E também no Brasil, conforme atestam pesquisas atuais. Mas elas nem sempre trabalham para países norte-americanos. Elas também trabalham para países da Europa. E quanto à Europa, nem todo o continente fala inglês, espanhol ou alemão, mas, em muitos casos, há um número significativo que fala francês, por exemplo na França, na Bélgica, na Suíça, e em outras partes da Europa. Nesse caso, os trabalhadores de dados falantes de francês são recrutados em ex-colônias do império francês e, depois, da república. Eles estão localizados na África. Isso tende a consolidar um desequilíbrio pós-colonial ou, pelo menos, disparidades de poder.
A situação na China é mais complicada porque a China tem um enorme mercado de trabalho interno e, em alguns casos, podem recrutar trabalhadores digitais e microtrabalhadores no sul da Ásia. Mas, em muitos casos, as empresas simplesmente recrutam internamente, ou seja, são trabalhadores chineses atuando para empresas chinesas que produzem automação ou, pelo menos, dizem que estão produzindo automação.
Então, depois disso tudo, eis a mensagem que quero deixar para vocês: Nós estamos aguardando por robôs, como [na peça teatral de Samuel] Beckett as pessoas esperavam Godot, aguardando que algo aconteça – uma completa automação, provavelmente – que nunca chegará sem a contribuição do trabalho digital humano.
Enquanto aguardamos por robôs, algo acontece na maneira como trabalhamos e na forma como trabalhamos nas plataformas. Porque, evidentemente, se os robôs não tiram os nossos postos de trabalho, isso não deve soar como uma boa notícia. Porque, nesse meio tempo, tem algo acontecendo. Os trabalhos estão se tornando mais precários. Em alguns casos, não contam com proteções sociais, como era antes. E, evidentemente, essa atividade humana é constantemente invisibilizada pelo que chamamos de automação. Portanto, deveríamos levar em conta essas coisas enquanto pensamos políticas e movimentos sociais para o futuro.