Um novo estudo do Google sobre inteligência artificial levanta questões sobre a ética da solução política determinada algoritmicamente.
O comentário é de Paolo Benanti, frei franciscano da Terceira Ordem Regular, professor da Pontifícia Universidade Gregoriana, em Roma, e acadêmico da Pontifícia Academia para a Vida. Em português, é autor de “Oráculos: entre ética e governança dos algoritmos” (Ed. Unisinos, 2020).
O artigo foi publicado em seu blog, 06-07-2022. A tradução é de Moisés Sbardelotto.
Uma das maiores dificuldades neste momento é construir uma inteligência artificial que se alinhe aos valores humanos. De fato, o problema do alinhamento não está resolvido. Para tentar resolver o problema, pelo menos em parte, pesquisadores da DeepMind do Google desenvolveram uma pipeline de pesquisa human-in-the-loop chamada “Democratic IA”, na qual o aprendizado por reforço é utilizado para projetar um mecanismo social que os humanos preferem majoritariamente.
Podemos substituir a política pelos algoritmos? Tentemos entender o que eles fizeram.
Os dados de treinamento da “Democratic IA”, esse é o nome do software, foram retirados de um grande grupo de pessoas que jogaram um jogo de investimento online que previa que a pessoa decidisse se queria manter uma dotação monetária ou compartilhá-la com outros para um benefício coletivo. A receita compartilhada era devolvida aos jogadores com base em dois mecanismos de redistribuição diferentes, um projetado pela inteligência artificial e outro pelos seres humanos.
A inteligência artificial identificou um mecanismo que corrigiu o desequilíbrio inicial da riqueza, puniu os free-riders e obteve a maioria dos votos. Ao otimizar para as preferências humanas, a inteligência artificial democrática oferece uma prova de conceito para a inovação política alinhada aos valores. Os resultados do estudo foram publicados na Nature Human Behavior [disponíveis em inglês aqui].
Estas são as notas introdutórias dos autores:
“Em nosso artigo recente, publicado na Nature Human Behaviour, fornecemos uma demonstração de prova de conceito de que o aprendizado por reforço profundo (RL) pode ser usado para encontrar políticas econômicas nas quais as pessoas votarão por maioria em um jogo simples. O artigo aborda, portanto, um desafio importante na pesquisa sobre inteligência artificial – como treinar sistemas de inteligência artificial que se alinhem aos valores humanos.
“Imaginemos que um grupo de pessoas decida reunir fundos para fazer um investimento. O investimento compensa, e obtém-se lucro. Como os rendimentos devem ser distribuídos? Uma estratégia simples é dividir o retorno igualmente entre os investidores. Mas isso pode ser injusto, porque algumas pessoas contribuíram mais do que outras. Alternativamente, poderíamos pagar a todos proporcionalmente ao tamanho do seu investimento inicial. Isso parece justo, mas e se as pessoas tivessem diferentes níveis de ativos, desde o início? Se duas pessoas contribuem com a mesma quantia, mas uma está doando uma fração de seus fundos disponíveis e a outra está doando tudo, elas deveriam receber a mesma parte dos lucros?
“Essa questão de como redistribuir recursos em nossas economias e sociedades tem gerado polêmica há muito tempo entre filósofos, economistas e cientistas políticos. Aqui, usamos o aprendizado por reforço profundo como um teste para explorar maneiras de resolver esse problema.
“Para enfrentar esse desafio, criamos um jogo simples que envolveu quatro jogadores. Cada partida do jogo foi jogada ao longo de 10 rodadas. Em cada rodada, cada jogador recebeu fundos, e o tamanho da dotação variava entre os jogadores. Cada jogador fazia uma escolha: poderiam manter esses fundos para si mesmos ou investi-los em um fundo comum. Os fundos investidos tinham a garantia de crescimento, mas havia um risco, porque os jogadores não sabiam como os rendimentos seriam divididos. Em vez disso, eles foram informados de que, nas primeiras 10 rodadas, haveria um árbitro (A) que tomaria as decisões de redistribuição, e, nas 10 segundas rodadas, um árbitro diferente (B) assumiria. No fim do jogo, eles votaram em A ou B e jogaram outro jogo com esse árbitro. Os jogadores humanos do jogo foram autorizados a manter os rendimentos desse jogo final, de modo a serem incentivados a relatar sua preferência de modo acurado.
“Na realidade, um dos árbitros era uma política de redistribuição pré-definida, e o outro foi projetado pelo nosso agente de aprendizado por reforço profundo. Para treinar o agente, primeiro registramos dados de um grande número de grupos humanos e ensinamos uma rede neural a copiar como as pessoas jogavam o jogo. Essa população simulada poderia gerar dados ilimitados, permitindo-nos usar métodos de aprendizado de máquina com uso intensivo de dados para treinar o agente de aprendizado por reforço profundo a maximizar os votos desses jogadores ‘virtuais’. Tendo feito isso, recrutamos novos jogadores humanos e colocamos o mecanismo projetado pela inteligência artificial frente a frente com linhas de base bem conhecidas, como uma política ‘libertária’ que devolve fundos às pessoas na proporção de suas contribuições.
“Quando estudamos os votos desses novos jogadores, descobrimos que a política projetada pelo aprendizado por reforço profundo era mais popular do que as linhas de base. De fato, quando realizamos um novo experimento pedindo a um quinto jogador humano para assumir o papel de árbitro e o treinamos para tentar maximizar votos, a política implementada por esse ‘árbitro humano’ era ainda menos popular do que a do nosso agente.
“Os sistemas de inteligência artificial às vezes são criticados por políticas de aprendizado que podem ser incompatíveis com os valores humanos, e esse problema de ‘alinhamento de valores’ se tornou uma grande preocupação na pesquisa sobre inteligência artificial. Um mérito da nossa abordagem é que a inteligência artificial aprende diretamente a maximizar as preferências (ou votos) declaradas de um grupo de pessoas. Essa abordagem pode ajudar a garantir que os sistemas de inteligência artificial tenham menos probabilidade de aprender políticas inseguras ou injustas. De fato, quando analisamos a política que a inteligência artificial descobriu, ela incorporou uma mistura de ideias que haviam sido propostas anteriormente por pensadores e especialistas humanos para resolver o problema da redistribuição.
“Em primeiro lugar, a inteligência artificial optou por redistribuir fundos para as pessoas em proporção à sua contribuição ‘relativa’ e não ‘absoluta’. Isso significa que, ao redistribuir os fundos, o agente considerou os meios iniciais de cada jogador, assim como a sua vontade de contribuir. Em segundo lugar, o sistema de inteligência artificial recompensou especialmente os jogadores cuja contribuição relativa foi mais generosa, talvez encorajando outros a fazerem o mesmo. É importante ressaltar que a inteligência artificial só descobriu essas políticas aprendendo a maximizar os votos humanos. O método, portanto, garante que os humanos permaneçam ‘no circuito’ e a inteligência artificial produza soluções compatíveis com humanos.
“Ao pedir às pessoas que votem, aproveitamos o princípio da democracia majoritária para decidir o que as pessoas querem. Apesar de seu amplo apelo, é amplamente reconhecido que a democracia vem com a ressalva de que as preferências da maioria são levadas em conta sobre as da minoria. Em nosso estudo, garantimos que – como na maioria das sociedades – essa minoria consistisse em jogadores mais generosamente dotados. Mas é necessário mais trabalho para entender como negociar as preferências relativas de grupos majoritários e minoritários, projetando sistemas democráticos que permitam que todas as vozes sejam ouvidas.”
Os autores do estudo são Raphael Koster, Jan Balaguer, Andrea Tacchetti, Ari Weinstein, Tina Zhu, Oliver Hauser (Universidade de Exeter), Duncan Williams, Lucy Campbell-Gillingham, Phoebe Thacker, Matthew Botvinick e Christopher Summerfield.
Raphael Koster, da DeepMind, está convencido de que “muitos dos problemas que os seres humanos enfrentam não são meramente tecnológicos, mas requerem uma coordenação na sociedade e nas nossas economias pelo bem comum. [...] Para poder ajudar, a inteligência artificial deve aprender diretamente os valores humanos”.
A equipe da DeepMind treinou a sua inteligência artificial para aprender com mais de 4.000 pessoas que também votaram nas suas políticas preferidas para a distribuição do dinheiro público. A política desenvolvida pela inteligência artificial após esse treinamento geralmente buscava reduzir as disparidades de riqueza entre os jogadores, redistribuindo o dinheiro público com base na quantia de dinheiro inicial que cada jogador tinha contribuído. Além disso, dissuadia os parasitas, devolvendo quase nada aos jogadores, a menos que tivessem contribuído com cerca de metade dos seus fundos iniciais.
Essa política idealizada pela inteligência artificial recebeu mais votos dos jogadores humanos do que uma abordagem “igualitária”, que previa a redistribuição dos fundos de modo igual, independentemente da contribuição de cada um, ou uma abordagem “libertária”, que distribuía os fundos com base na proporção da contribuição de cada um ao prato público. “Uma coisa que achamos surpreendente é que a inteligência artificial aprendeu uma política que reflete uma mistura de opiniões provenientes de todo o espectro político”, diz Christopher Summerfield, da DeepMind.
Quando havia a máxima desigualdade entre os jogadores no início, uma política “liberal-igualitária” – que redistribuía o dinheiro com base na proporção de fundos iniciais que cada jogador havia contribuído, mas não desencorajava os free-riders – se mostrou popular assim como a proposta da inteligência artificial, obtendo mais de 50% dos votos em uma competição direta.
Os pesquisadores da DeepMind alertam que o seu trabalho não representa uma receita para um “governo da inteligência artificial”. Eles dizem que não têm planos de construir instrumentos alimentados pela inteligência artificial para a formulação de políticas.
Talvez seja justo assim, porque a proposta da inteligência artificial não é necessariamente única em relação àquilo que já foi proposto por outros, afirma Annette Zimmermann, da Universidade de York, no Reino Unido. Zimmermann também alertou contra o foco em uma ideia estreita de democracia como um sistema de “satisfação das preferências” para encontrar as políticas mais populares.
“A democracia não se limita a vencer, a fazer com que a política que mais agrada seja implementada. Trata-se de criar processos em que os cidadãos possam se encontrar e deliberar entre si em pé de igualdade”, diz Zimmermann.
Os pesquisadores da DeepMind levantam a preocupação de uma situação de “tirania da maioria” alimentada pela inteligência artificial, na qual as exigências das pessoas pertencentes a grupos minoritários sejam negligenciadas. Mas essa não é uma grande preocupação entre os cientistas políticos, como afirma Mathias Risse, da Universidade de Harvard. Segundo ele, as democracias modernas devem enfrentar um problema maior: os “muitos” são privados dos seus direitos pela pequena minoria da elite econômica e abandonam totalmente o processo político.
No entanto, Risse afirma que a pesquisa da DeepMind é “fascinante” pelo modo como fornece uma versão da política do igualitarismo liberal: “Já que estou no campo do liberal-igualitarismo, acho isso um resultado bastante satisfatório”.
A questão que parece significativa é esta:
“Tendo definido as observações, assim como o objetivo que desejávamos maximizar, estimamos o gradiente da política, ou seja, o gradiente do objetivo (o número médio de votos) em relação aos parâmetros da política (os pesos da rede gráfica) voltando-nos para a estrutura SCG. Notamos aqui que a maior parte da computação no jogo de investimento é diferenciável (incluindo a política implementada pelo HCRM), e as políticas de jogadores humanos virtuais, cujo espaço de ação é discreto, são a única exceção. A estrutura SCG generaliza o teorema do gradiente da política e nos permitiu obter um estimador de baixa variância do gradiente da política por autodiferenciação, por meio do ambiente e do mecanismo da política, enquanto compensava as operações não diferenciáveis (as contribuições discretas dos jogadores). O objetivo substituto para o gradiente da política foi o seguinte:
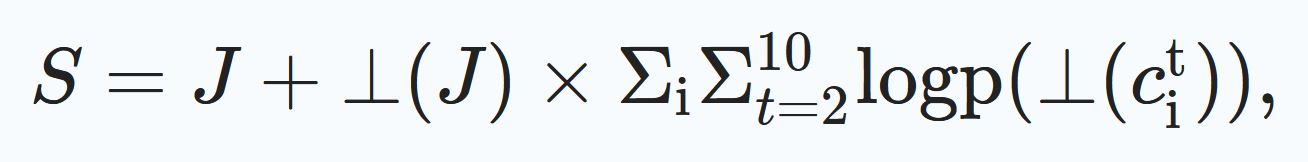
“... onde S é o objetivo substituto, J é o objetivo que desejamos maximizar por episódio (o número esperado de votos) e ⊥ é a operação de gradiente de parada. Note-se que, para o segundo termo, o gradiente só pode fluir através da parametrização da probabilidade logarítmica da política do jogador. Observe-se também que as contribuições da primeira rodada são removidas da equação, pois não dependem dos parâmetros do mecanismo. Na prática, adicionalmente, escolhemos o centro médio J dentro de um lote, porque isso é conhecido por reduzir a variância do estimador de gradiente.”
Das muitas perguntas que podem ser levantadas, gostaria de fazer pelo menos uma.
Parece-nos que a ética da solução política determinada algoritmicamente está ligada a uma matematização do processo decisório do ponto de vista da teoria dos jogos. Pressupõe-se que a escolha confiada à máquina deveria ser tolerada particularmente quando as atividades põem em jogo algo que não é de “soma zero” e quando a importância do processo tem mais peso do que a importância do resultado.
É preciso prestar atenção à expressão técnica “non-zero-sum” que descreve uma propriedade matemática da chamada teoria dos jogos (ou seja, a ciência matemática que, por um lado, analisa as situações de conflito e busca soluções competitivas e cooperativas por meio de modelos, e, por outro, oferece um estudo das decisões individuais em situações em que há interações entre os diversos sujeitos, de modo que as decisões de um sujeito podem influenciar os resultados alcançáveis por um rival, de acordo com um mecanismo de retroação).
Na teoria dos jogos, um “jogo de soma zero” descreve uma situação em que o ganho ou a perda de um participante é perfeitamente contrabalançado por uma perda ou um ganho de outro participante (se subtrairmos a soma total das perdas da soma total dos ganhos, obteremos zero).
Em vez disso, as situações em que os participantes podem ganhar ou perder juntos são chamadas de “não de soma zero”. Por exemplo, se um país com um excesso de trigo comercializa com outro país que tem um excesso de leite, ambos se beneficiam com a transação: estamos diante, portanto, de um “jogo não de soma zero”. No entanto, o benefício da soma não corresponde necessariamente ao bem buscado: quer-se tratar o problema como um processo de maximização dos resultados, ou seja, como um processo com o qual se pode obter o maior lucro, e não como uma análise ética dos valores a serem afirmados na regulamentação tecnológica.
Dito com um exemplo: uma bomba atômica mata muito mais do que uma pistola e talvez até leve a vencer uma guerra. Acho muito difícil defini-la como uma boa solução política ou, melhor, como uma solução democrática...